

TCP has been running the internet for decades and has gone over many enhancements and development cycles since it was first created. A lots of engineering work was put out to keep it relevant as the internet grows bigger and more protocols and applications requirement were created.
This is a series of multiple parts that addresses TCP performance in different environments, conditions and networks and explains how it can be tuned to perform better. The series is meant to target network professionals who work on troubleshooting packets capture and Sys/Application developers who are looking for ways to optimize their applications to perform better in different network conditions. It’s assumed that the reader has a bit of understanding on how TCP works from a practical perspective.
In this part, we’ll discuss TCP Receive Window and the impact of this TCP field on the performance of a TCP conversation.
In a nutshell, TCP Receive Window is a 16 bit field in the TCP header that defines the amount of buffer space in bytes that it can receive at a particular moment of time. Obviously the maximum value would be 2^16 – 1 = 65535 bytes, which might look a low number compared to the current high speed networks where we see 400Gbps ethernet is seeing a quick adoption in the industry pushed by the current cloud dominance and the increased demand for fat pipes to migrate data to the cloud, however the actual value of the receive buffer space that the OS allocates would be in reality the receive window buffer multiplied by the scaling factor which we will discuss in a separate article but for now, it’s important to know that if the scaling factor is negotiated in the TCP three way handshake, then the actual value of the receive window would be the receive window multiplied by the scaling factor.
Technically speaking, the sender always considers this value when specifying the congestion window [sending window] as it should not exceed the advertised receive window which means that if the advertised receive window is low, the sender will adjust its sending window accordingly which will untimely lead to low throughput and slow transfer rate.
The value of the TCP receive window is allocated by the OS and it depends on many factors such as the available memory to the OS and how busy the host is, MSS value and if TCP timestamps is used. However, in some cases especially for file transfers over high latency networks which are subject to BDP (Bandwidth Delay Product), it’s necessary to manually adjust the TCP receive window. We’ll discuss the BDP in more details in a separate article of this series. With that being said, let’s get jump in into a packet capture and see what’s going on.
In this example, we have a slow SCP file transfer from 10.10.18.142 to 3.236.129.61. Using Wireshark throughput graph, we can see the average file transfer rate is around 18.75 Kbytes/second which is very low.

Let’s examine the conversation and see what’s causing this slow file transfer. Wireshark can calculate the outstanding data that have been sent out but not yet acknowledged which represents the actual transfer rate at certain point of time. The filter name is called “tcp.analysis.bytes_in_flight”
Now let’s create a column and call it “Bytes in Flight” and add this filter value to see how much is being sent out at any moment of time:

As you can see it’s around 2.8 Kbytes which is low. Let’s dig further and examine the advertised receive window of host 3.236.129.61 and see if its value is actually holding off the sender 10.10.18.142.
To visualize this, you can use create another column for the receive window. Wireshark makes it easy by providing the actual receive window after multiplying it by the scaling factor in case it’s used.

Now looking at the calculated receive window we can see the value is 4096 bytes which is very low.
Remember the sender does not send more than what the receiver is advertising in its receive window. The question becomes now why did the OS decide to allocate that value?
To answer this question, as mentioned before the OS would need to be inspected to see how busy it is. But before even going in that direction, if we take a look at the actual receive window value and calculate the maximum possible transfer rate that the sender can have using this equation:
Transfer rate in bytes = TCP receive window size in bytes * (1 / connection latency in seconds)
Considering the above equation, we have the following information:
TCP receive window = 4096 bytes
Latency: 190 msec.
You might be wondering where that number came from. If you watch the difference in time between two consecutive packets from the sender and receiver respectively, you will see it’s close to 190 msec or 0.19 second. An easy way in Wireshark is to utilize a handy column with filter value of: “tcp.time_delta”
Now if you do the math based on the above equation, you’ll see the maximum transfer rate is 21.55 Kbytes/second.
Assuming that the host is underutilized, we can inspect the Kernel TCP settings to see the current values. Now depending on the OS being used, if using Linux, a quick check would be to run this command at the receiver side:
sysctl -a | grep net.ipv4.tcp_rmem

The setting of net.ipv4.tcp_rmem defines minimum, default and maximum size of the TCP socket receive buffer. A bit of a context about these values:
The minimum represents the smallest guaranteed receive buffer size during lack of system memory. The minimum value defaults to 4096 bytes. The default value represents the initial size of a TCP sockets receive buffer. The default value for this setting is 87380 bytes. Finally the maximum represents the largest receive buffer size automatically selected for TCP sockets. The default value for this setting is somewhere between 87380 bytes and 6M bytes based on the amount of memory in the system.
From the output above, we can see the minimum is 1024 bytes and the maximum is 8192 bytes which are very low. To rectify this, we can simply increase these numbers with careful consideration to the host total memory.
For the sake of demonstration, I’ve used the numbers below:

Let’s now examine the file transfer after making this change:

With transfer rate close to 7.5 Mbytes/second, obviously we can see a huge improvement over the previous case where the transfer rate was around 18.75 Kbytes/second.
Now in the case of Windows operating systems, particularly Windows Vista, Windows Server 2008, and later versions of Windows, the Windows network stack uses a feature that is named TCP receive window Autotuning level to set the TCP receive window size with initial value of 16K bytes. This feature can negotiate a defined receive window size for every TCP communication during the TCP Handshake.
To check the current settings of TCP receive window Autotuning, we can either use netsh utility or Powershell command:
Get-NetTCPSetting | Select SettingName,AutoTuningLevelLocal
I prefer to use Powershell as it’s more elegant and provides better control over the parameters.
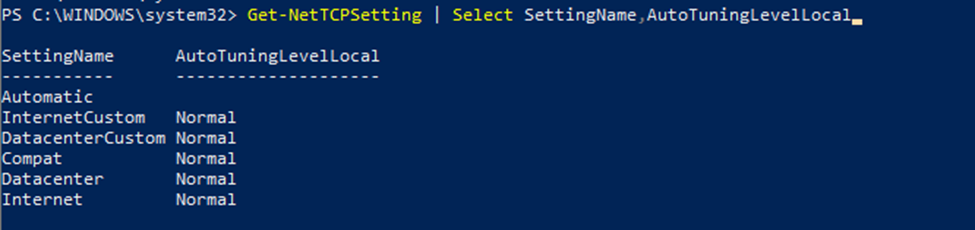
As you can see, Windows OS deploys five profiles namely:
InternetCustom, DatacenterCustom, Compat, Datacenter and Internet. These profiles come out of the box with certain TCP configurations including the setting of TCP receive window Autotuning. However, in some cases, the configurations of the profile being used might not be appropriate or doesn't harmonize with the actual network behavior such as a very high latency of a satellite connection or cross-continent replication and this is where a manual change is needed to adjust the configuration particularly the Autotuning.
Currently there are five levels of Autotuning which are described below based on Microsoft documentation:
Normal (default) | Set the TCP receive window to grow to accommodate almost all scenarios. |
Disabled | Set the TCP receive window at its default value. |
Restricted | Set the TCP receive window to grow beyond its default value, but limit such growth in some scenarios. |
Highly Restricted | Set the TCP receive window to grow beyond its default value, but do so very conservatively. |
Experimental | Set the TCP receive window to grow to accommodate extreme scenarios. |
Now, you might be wondering how Windows OS decides which profile and hence Autotuning level to use?
The answer is actually by matching the conversation parameters to the profile settings.
Let's take a quick look at this command and see its outputs:

We can see that by default, Windows OS is using Internet profile because it covers TCP and the entire range of ports. Now to see which Autotuning level is configured for this profile, we can use the command:

To see which active connections per profile, you can use the command:

Now If you want to instruct Windows OS to use certain profile such as the Datacenter profile when traffic is destined to 192.168.0.0/16 network, we can use the PowerShell command below:

The same way if we want to use certain profile for a certain application. We can define the ports that the application uses and then associate the profile.

In summary, we can see the significance of the TCP receive window, how it affects the throughput and how to tune it to match your requirements given that hosts have enough resources and the connection medium does provide enough capacity or bandwidth.
In Part 2, we will explore TCP window scaling option and Bandwidth Delay Product aka BDP.
Comentários